PROJECT COLLABORATORS: Eduardo Navas || Luke Meeken || Robbie Fraleigh || Kory Blose || Aaron Knochel ||
FORMER COLLABORATOR (2022 - 2024): Heidi Biggs ||
“Elephant in the Dark” is a web-based tool designed to showcase how the meanings of words can shift depending on the data used to fine-tune artificial intelligence (AI) systems. The name “Elephant in the Dark” is a reference to the parable about a group of men who cannot see an elephant (in some versions because they are blind, in other versions because they are in a darkened room), and try to determine the animal's qualities by feeling its contours. This tool is designed to help surface particular qualities of different text corpuses by allowing users to explore their semantic contours.
This beta app is part of Remix Research Lab’s broader investigation into how AI reshapes the way humans understand and use language, particularly focusing on biases and the potential loss of context in AI-generated content, which could lead to what is also known as data noise, which appears in prompt-based text production when a generative model provides inaccurate historical and/or factual content. In images, the result can be perceived when part of an image is distorted, such as missing fingers, or distorted eyes, or landscapes.
“Elephant in the Dark” utilizes Word2Vec, an algorithm that discerns word meanings by examining the contexts in which they appear, similar to how one might learn a language by listening to conversations. This algorithm builds its understanding by observing the words that frequently co-occur. The meanings are then encoded as numerical data, known as “embeddings.” These embeddings are essential as they enable the model to comprehend the nuances and relationships between words, shedding light on how language operates across various contexts.
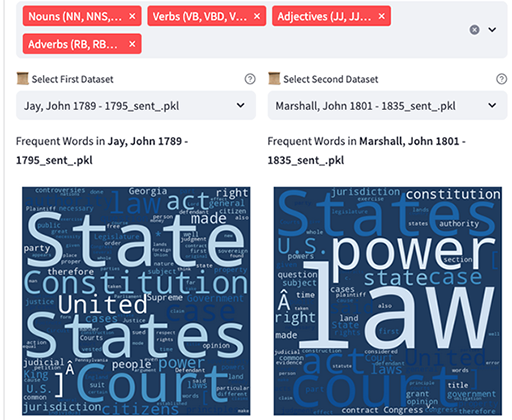
The app compares two texts to extract words related to the word entered on the top right. The neural net was developed as a Streamlit (https://streamlit.io/) application that leverages natural language processing techniques and word embedding models to compute and compare semantic similarity scores between target words and words from two selected textual corpora. In the application, we use Word2Vec (https://arxiv.org/pdf/1301.3781.pdf) as a language model that learns to represent words as dense vectors in a multi-dimensional space. These vectors capture semantic relationships between words based on their contexts within the provided text data. Once the neural net analysis is complete, results are extracted as datasheets.
This initial training phase produces what is known as a “pre-trained” model. To enhance its capabilities for specific tasks—such as summarization, question and answer, document classification, or content generation—the model can then undergo a process called fine-tuning. During fine-tuning, the model is adjusted to improve its performance on specific types of data or user-specific data. For example, a model trained on general English might be fine-tuned with a collection of legal documents to better understand and process legal language. Our role as researchers in turn is to consider how the list of words (cultural objects) may relate to the pre-existing sources at a cultural level (as connotation)—that is according to qualitative assessment.
Remix principles are at play throughout the process described above at a denotational level. Our app evaluates patterns of repetition to create lists of words that are reused in different datasets, which we continue to expand. The neural net app in this case considers how words part of a list recur (remixed or reused in different contexts) throughout the dataset by considering how words are repeated semantically.
It would not be wise to make major claims about specific trends with measured precision, but the list of words, which can be evaluated in the selected datasheets which can be created by anyone using the beta app, provide a general sense of the types of issues and cultural topics. How the words are extracted and analyzed is explained on the actua app webpage.
AI models like GPT-4, released on March 13, 2024, are trained on vast amounts of textual data, with GPT-4 itself having been trained on 10 trillion words. Models of this size require powerful computer hardware for effective operation. In contrast, smaller models such as Word2Vec, which is trained on the Google News dataset containing about 100 billion words, specialize in capturing semantic relationships between words within that specific corpus and can be operated on a modern laptop. We initially uploaded our neural net app on HuggingFace [include link here], a community platform for submitted AI models currently hosts hundreds of user models, many of which rely on word embeddings within their model architecture. We are now making our second beta version available for online users to experience how the datasets we choose can be explored. We plan to continue development of Elephant in the Dark as our search continues.